Ludovico Rella
07/24/2023 | Reflections
This post explores the relationship between the recent explosion of Artificial Intelligence applications and the material, economic and epistemological role that hardware played in that explosion. As Transformers like ChatGPT and Diffusion Models like Midjourney, Stable Diffusion or DALL-E took the internet by storm, Nvidia, the leading graphic card manufacturer, overtook 1 trillion dollars in market capitalization. The connection between these two facets of the AI boom lies in an often overlooked relationship between AI and hardware. This post provides some cues for navigating this topic, drawing on a recently published article in Social Studies of Science (Rella, 2023). Here I will also argue that a renewed attention to hardware requires an engagement with a broader set of methodological tools and data sources, and in particular close observation of industry developments through events such as the AI Hardware & Edge Summit 2023.
While AI research has successfully unpacked the ethico-politics and epistemology of software and algorithms (Amoore 2021, Amaro 2023), I argue that hardware is just as important a battleground where interests and epistemologies play out. In particular, I draw on Luke Munn’s concept of epistemic infrastructures to show that the materiality of computational infrastructures crystallizes specific ways of thinking and knowing. For example, “fast knowledge” in terms of computing power and speed, is crystallized, while other forms of knowing that are more “communally and ecologically focused” are discarded (Munn, 2022, p. 1406). In my own research, I found that the micro-materiality of the chips where the individual computational instructions are run is as important as the macro-materiality of datacentres, and the abstract software architectures of the algorithms themselves. I show that GPUs make possible and feasible certain algorithmic calculations, and at the same time discard others.
The micro-materialities of GPUs
GPUs, as opposed to the Central Processing Units (CPUs) that are the “brain” of our computers, operate a form of massively parallel computing, i.e., they are able to spread the execution of the same instructions on multiple data simultaneously by dividing the microchip into blocks, each including a number of threads which in turn execute individual instructions (see Figure 1). Their original business case was to render 3D environments in video games; something that requires constantly changing the shading of the surface of digital objects in real time, which is done by changing the value of several pixels simultaneously. Conversely, CPUs have access to more memory and are faster in terms of time devoted to a specific instruction, but they only have a limited number of instructions that they can run simultaneously. In this way, they are more powerful when used for sequential, rather than parallel, tasks.
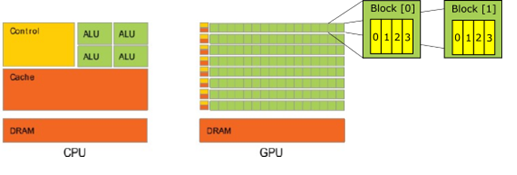
Geopolitical and Economic Significance
If microchips, like GPUs, contribute to shape thought and action, then a study of AI requires us to pay attention to hardware as an ethical and political battleground. This is all the more important as the AI hardware industry, in a similar way as the software side of it, is moving towards more application-specific and closed models. The latest GPT4 model is described in a white paper by OpenAI, but it does not describe any technical details of the architecture – number of layers, number of parameters, etc.
On the hardware side of things, the semiconductors industry is notoriously concentrated, and GPUs are no different. The semiconductor market was worth $ 555.9 billion as of 2021, up 26.2% from just 2020, projected to hit $ 1 trillion by 2030. Taiwan and Korea, and in particular TSMC and Samsung, share a duopoly, respectively with a 53% and 17% of the global semiconductor foundry market, and essentially representing the entirety of microchips with transistors smaller than 10nm. As of 2022, out of the Top 500 list of supercomputers, NVIDIA provides graphic acceleration for a combined 92.46% of the total 146 devices that use accelerators. According to market research, Nvidia’s revenue from cloud computer is 80% of the whole sector. While the hardware used in datacentres so far has been general-purpose GPUs, powered by CUDA as a general-purpose coding framework, the launch of application-specific architectures like Google’s Tensor Processing Units (TPUs) seems to indicate a move towards a stronger “hardware-software codesign”, which might also mean weaker exchange between developer communities working on different models.
Some Methodological Conclusions
This invitation to attend to the ethico-politics of hardware requires not only conceptual, but also methodological updates and considerations. Hardware is an industry highly protected by industrial secrecy, if not outright fenced by geopolitical and national security clearance walls. Patents and other forms of intellectual property disclosure can help to navigate the landscape of new devices and applications, as well as requesting demonstrations on hardware companies’ websites. For those of us aiming to develop knowledge of the design and deployment of AI, there are opportunities, for example, in ethnographic and autoethnographic research into the use of Edge devices like Raspberry Pi, Arduino or Nvidia Jetson.
A source of untapped potential to obtain new data lies in forms of temporary ethnographies in trade fairs and expos, in this case the AI Hardware & Edge Summit 2023, to be held in person in Silicon Valley in September. The AI Hardware Summit contains keynotes and fireside chats with leading experts which can provide very important insight into the epistemology of AI research. These events provide windows into the political economy and cultural economy of the hardware industry, working as tournaments of value where resources, prestige and imaginaries are negotiated across the industry. Temporary ethnography is a very important tool for social scientists, one that should acquire more prominence, especially in the study of fast-changing industries. I will participate in the AI Hardware & Edge Summit, and I hope to report back in the future with further reflections from the field.
Ludovico Rella is an Assistant Editor of Backchannels, and a Postdoctoral Research Associate in Geography at Durham University, in the ERC research project Algorithmic Societies. His PhD focused on cross-border payments and blockchain technologies. He currently studies the infrastructural materiality of AI, and AI for economic policy making. He published in the Journal of Cultural Economy, Political Geography, and Big Data & Society, and authored chapters in books published by Elsevier, Springer, and Manchester University Press.
Published: 07/24/2023