
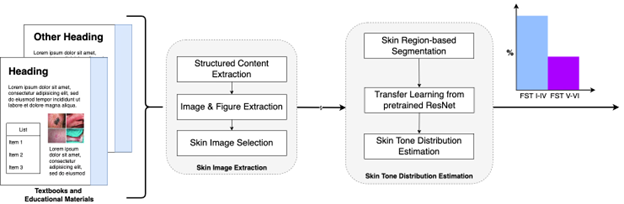
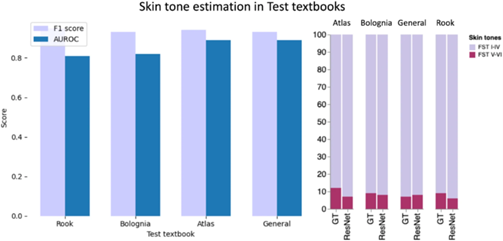
Previous analysis of dermatology-related academic materials (journals and textbooks) has shown an under-representation of FST V and VI; however, images were annotated and analyzed manually, i.e., a domain expert located each image in a textbook and labeled the skin tone. Unfortunately, this manual approach is not tractable for a large corpus due to its labor-intensive nature, operator visual fatigue, and intra-inter-observer error of skin tone labeling. As part of our research, we provided an open-source pipeline to automatically quantify the imbalanced representation of binary skin tones in textbooks (FST I-IV and FST V-VI); while this means we do not capture further granularity in skin tones, it does assess the most historically excluded skin tones. We evaluated our method in four medical textbooks, where brown and black skin tone images made up only 10.5% of all skin images.
Putting this work together required an interdisciplinary team with diverse skill sets across several continents and institutions, from Nairobi, Kenya (where I’m based, as well as other co-authors) to Zurich, Switzerland, and Stanford, USA. The dermatologists on the team identified the problem. They labeled innumerable figures from textbooks to serve as baseline and training data for the ML methods, and they actively participated in validating each step of the proposed solution. The ML scientists improved the process of extracting figures from the entire document. They refined models previously created for identifying non-diseased patches of skin in images and estimating their tone.
With our proposed new pipeline, we were able to recapitulate the findings in the literature, which shows a significant underrepresentation of FST V-VI skin in dermatology educational materials. This project allows for the running of bias assessments at scale without the need for hours spent labeling manually. We envision this technology as a tool for medical educators, publishers, and practitioners to help assess skin tone diversity in their educational materials, setting a minimum standard for authors and publishers to follow, thus helping to improve health equity. This work is an excellent example of ML serving not to replace but to aid doctors in improving their training and making them more effective.
_______________
Celia Cintas is a Staff Research Scientist at IBM Research Africa, based in Nairobi. She is a member of the AI Science team at the Kenya Lab. Her current research focuses on the improvement of ML techniques to address challenges in global health and exploring subset scanning for anomaly detection under generative models.
Published: 02/10/2025